Meta-Harness: LLM을 감싸는 코드를 자동으로 진화시키기
모델은 그대로 두고, 하네스만 바꿔 성능을 끌어올리는 outer-loop 시스템. 논문과 레퍼런스 구현을 코드 단위로 뜯어본다.
1. Harness란 무엇인가?
LLM 시스템의 성능은 모델 가중치만으로 결정되지 않는다. 모델을 감싸는 harness, 즉 무엇을 저장하고, 가져오며, 모델에 보여줄지 결정하는 코드가 성능에 결정적인 영향을 미친다. 실제로 같은 벤치마크에서 harness만 바꿔도 성능이 6배까지 차이 나는 것이 관찰되었다. 자동차에 비유하면 모델은 엔진이고 harness는 차체다. 같은 엔진이라도 차체 설계에 따라 연비, 최고 속도, 핸들링이 완전히 달라지는 것과 같은 이치다.
구체적으로 harness가 하는 일을 코드 레벨에서 살펴보자. 온라인 텍스트 분류 태스크를 예로 들면, LLM이 새로 들어오는 텍스트의 카테고리를 맞추는 문제를 풀어야 한다. 이때 harness는 이전에 맞추거나 틀린 예시들을 메모리에 저장해두고, 새 텍스트가 들어오면 그 메모리에서 가장 관련 높은 예시들을 꺼내 "이런 예시들이 있었으니 이 텍스트의 카테고리를 맞춰봐"라는 프롬프트를 구성해서 모델에게 보여주는 역할을 한다. 어떤 예시를 몇 개 보여줄지, 어떤 순서로 보여줄지, 비슷한 예시만 보여줄지 아니면 헷갈리기 쉬운 대조 쌍도 함께 보여줄지에 따라 정확도가 크게 달라진다.
에이전트 코딩 태스크에서는 harness의 역할이 더 넓어진다. LLM이 터미널에서 복잡한 프로그래밍 과제를 자율적으로 수행해야 하는데, 이때 harness는 LLM에게 어떤 도구(셸 명령어, 파일 편집 등)를 제공할지(_call_llm_with_tools), 도구 실행 결과를 어떻게 가공해서 다시 LLM에게 보여줄지(_execute_commands), 대화가 길어져서 컨텍스트가 넘칠 때 이전 내용을 어떻게 요약할지(_summarize_context) 등을 결정하는 전체 scaffold가 된다.
이런 harness 설계는 지금까지 대부분 수작업이었다. 엔지니어가 실패 사례를 관찰하고, 휴리스틱을 조정하고, 소수의 설계안을 시도해보는 과정을 반복해야 했다. Meta-Harness는 이 과정 자체를 자동화할 수 있는지 묻는 논문이다. 한마디로 정의하면, Meta-Harness는 harness를 자동으로 진화시키는 harness다.
2. 기존 텍스트 옵티마이저의 한계
harness 최적화와 가장 가까운 기존 연구 분야는 텍스트 최적화다. OPRO, TextGrad, AlphaEvolve, GEPA 같은 방법들이 프롬프트나 코드 아티팩트를 반복적으로 개선한다. 하지만 이 방법들에는 근본적인 한계가 있다. 이전 시도에서 얻은 피드백을 심하게 압축해서 다음 시도에 전달하기 때문에, 왜 이전 시도가 실패했는지를 추적할 수 있는 정보가 대부분 사라진다.
이 차이를 이해하려면 각 방법이 iteration마다 얼마나 많은 정보를 볼 수 있는지(MTok/iter, 즉 iteration당 백만 토큰 단위의 컨텍스트)를 비교해보면 된다.
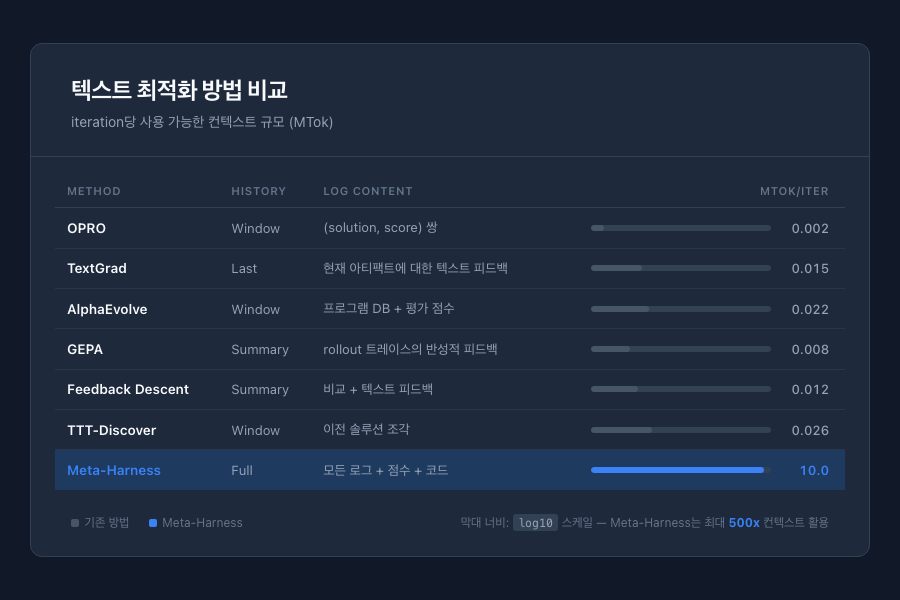
표에서 "History" 열은 이전 시도들을 얼마나 볼 수 있는지를 나타낸다. "Window"는 최근 몇 개만, "Last"는 바로 직전 것만, "Summary"는 LLM이 요약한 것만 본다는 뜻이다. "Log content"은 무엇을 피드백으로 받는지를 보여준다. OPRO는 "(이 코드를 썼더니 42점이었다)" 같은 점수 쌍만 받고, TextGrad는 "이 부분을 이렇게 바꿔봐라"라는 텍스트 피드백만 받는다.
핵심적인 차이는 MTok/iter 열에 있다. 기존 방법들은 iteration당 100에서 30,000 토큰의 피드백을 사용하는 반면, Meta-Harness는 10,000,000 토큰, 즉 약 500배에서 5,000배 더 많은 진단 정보에 접근한다. Meta-Harness만 유일하게 "Full" 히스토리를 사용하며, 이전 모든 후보의 소스 코드, 평가 점수, 그리고 각 예제별 실행 로그 전체를 파일시스템을 통해 볼 수 있다.
왜 이렇게 많은 정보가 필요할까? Harness는 저장, 검색, 프롬프트 구성이 연쇄적으로 영향을 주는 시스템이기 때문이다. 검색 로직의 작은 변경이 프롬프트 구성에 영향을 주고, 그게 다시 모델의 추론에 영향을 준다. 예를 들어 "이전 후보의 정확도가 42%였습니다"라는 점수 요약만으로는 어디서 어떤 예제를 왜 틀렸는지 알 수 없다. 실행 로그를 직접 읽어야 "아, 이 예제에서 검색된 유사 예시가 사실은 다른 카테고리였구나"처럼 실패 원인을 추적할 수 있다. 논문의 ablation study에서도 점수만 보여줬을 때 median 34.6%, 점수+요약 34.9%, 전체 실행 로그 접근 시 **50.0%**로, 실행 로그 접근이 성능 향상의 핵심 요인이었다.
3. Meta-Harness Search Loop
Meta-Harness의 핵심은 단순한 3단계 루프다.
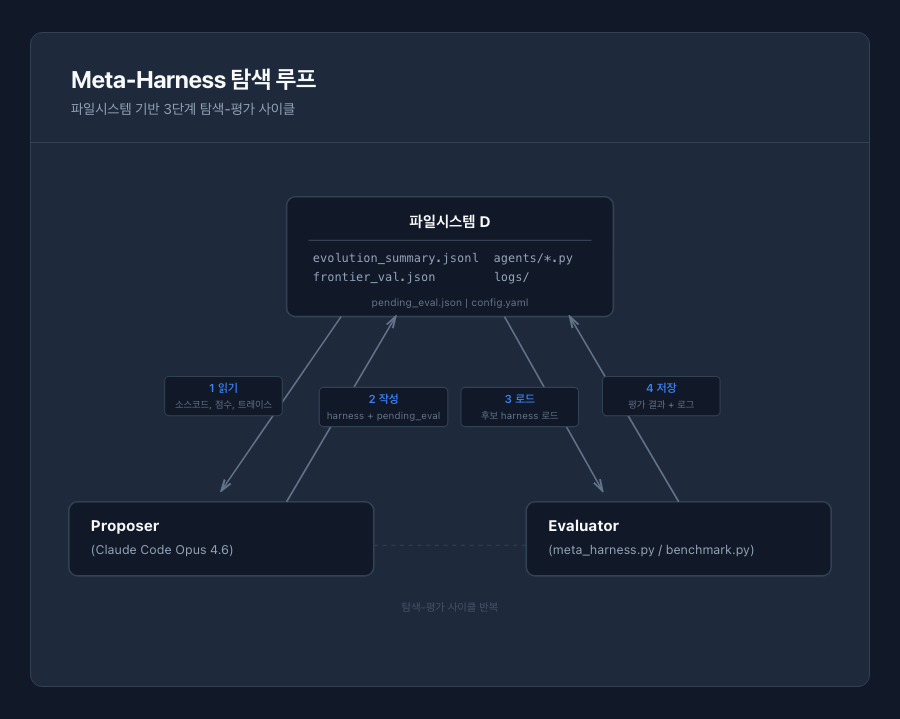
Step 1: 파일시스템 읽기. Proposer라고 불리는 코딩 에이전트(Claude Code Opus 4.6)가 이전 모든 후보의 소스 코드, 평가 점수, 실행 로그가 저장된 디렉토리를 탐색한다. Proposer는 Read, Glob, Grep 같은 파일 탐색 도구를 사용해서 evolution_summary.jsonl(지금까지 시도된 모든 후보와 그 결과), frontier_val.json(현재 최고 성능 시스템), 그리고 각 후보의 실행 로그를 선택적으로 읽는다. 논문의 측정에 따르면 proposer는 iteration당 평균 82개의 파일을 읽으며, 이전 20개 이상의 후보를 참조한다.
Step 2: 새 harness 제안. Proposer가 Step 1에서 분석한 결과를 바탕으로, 기존 코드를 복사한 후 개선 사항을 적용하여 새로운 harness 코드 파일(agents/<name>.py)을 작성한다. 그리고 아래와 같은 pending_eval.json 파일에 후보의 메타데이터를 기록한다.
{
"iteration": 3,
"candidates": [
{
"name": "contrastive_retrieval",
"file": "agents/contrastive_retrieval.py",
"hypothesis": "비슷하지만 라벨이 다른 대조 쌍을 보여주면 경계 구분이 개선된다",
"axis": "exploration",
"base_system": "fewshot_all",
"components": ["contrastive_pairs", "query_anchored_pairing"]
}
]
}
이 파일은 Proposer가 "이런 가설을 세웠고, 이 코드 파일에 구현했다"고 outer loop에 전달하는 약속된 형식이다. 텍스트 분류에서는 iteration당 3개, TB2에서는 1개의 후보를 제안한다.
Step 3: 평가 후 로그 저장. meta_harness.py가 pending_eval.json을 읽어서 각 후보를 자동으로 평가한다. 텍스트 분류의 경우 benchmark.py를 호출해서 모든 데이터셋(USPTO, Symptom2Disease, LawBench)에서 val accuracy를 측정하고, TB2의 경우 harbor_run()을 호출해서 89개 task를 최대 50개까지 동시에 실행한다. 평가가 끝나면 모든 결과(제안된 코드, 추론 트레이스, 평가 점수)를 파일시스템에 저장하고 다시 Step 1로 돌아간다.
여기서 "Proposer가 Claude Code Opus 4.6이면 내장된 도구가 많지 않나?"라는 의문이 들 수 있다. 실제로 Meta-Harness는 proposer가 사용할 수 있는 도구를 의도적으로 최소한으로 제한한다.
PROPOSER_ALLOWED_TOOLS = [
"Read", # 파일 읽기
"Glob", # 파일 패턴 매칭으로 찾기
"Grep", # 코드 내 문자열 검색
"Agent", # 서브에이전트 생성 (TB2에서만 사용)
"Write", # 새 파일 생성
"Edit", # 기존 파일 수정
"Bash", # 셸 명령어 실행
]
웹 검색, MCP 서버, 슬래시 커맨드 등은 모두 비활성화된다(--disable-slash-commands, --strict-mcp-config). Proposer는 순수하게 로컬 파일시스템과 코드 편집만으로 작업한다.
4. 코드 구조 Deep Dive
Meta-Harness 저장소에는 두 개의 완전한 참조 구현이 있다. 하나는 온라인 텍스트 분류를 위한 메모리 시스템 탐색이고, 다른 하나는 TerminalBench-2를 위한 에이전트 스캐폴드 진화다.
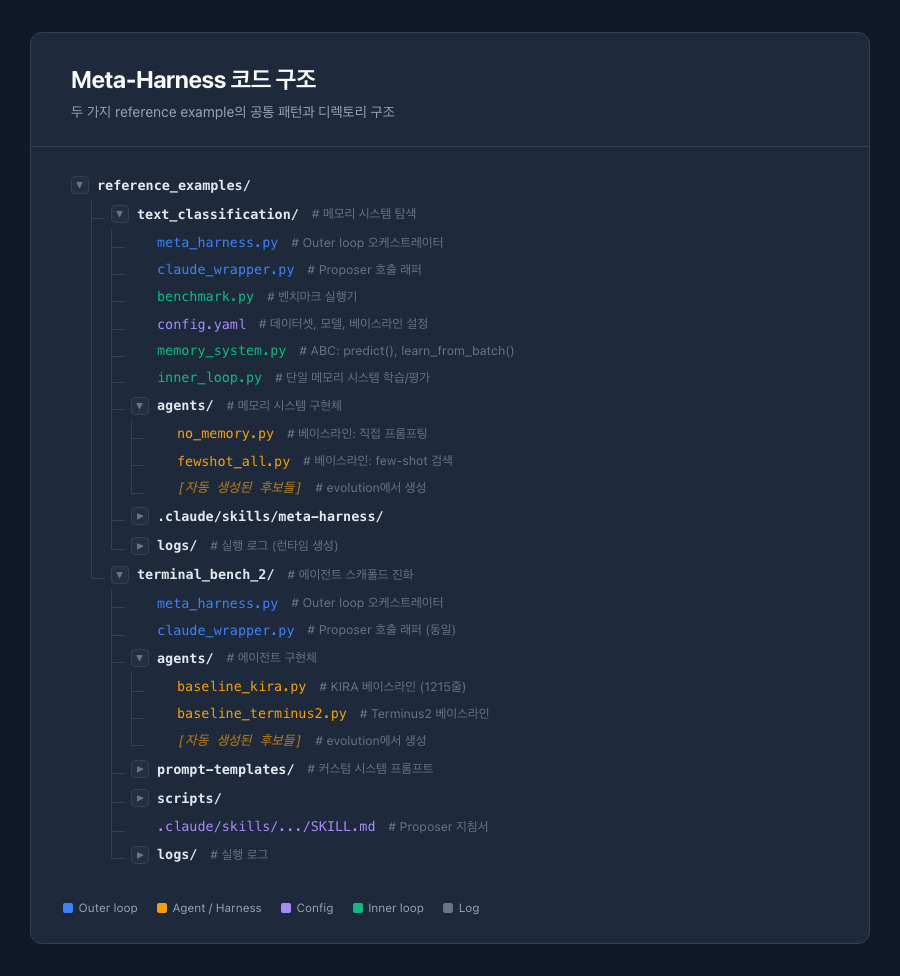
두 구현은 동일한 아키텍처 패턴을 따른다. meta_harness.py가 전체 evolution 루프를 관리하고, claude_wrapper.py가 Claude Code CLI를 호출하여 proposer 세션을 실행하며, SKILL.md가 proposer에게 역할, 제약, 산출물 형식을 지시한다. 새로 생성되는 harness 후보들은 모두 agents/ 디렉토리에 저장된다.
각 핵심 파일의 역할을 슈도 코드로 정리하면 다음과 같다.
meta_harness.py (Outer Loop 오케스트레이터)
def run_evolve():
# Phase 0: Baseline 평가
for baseline in ["no_memory", "fewshot_all"]:
benchmark.run(baseline) # 모든 데이터셋에서 평가
update_frontier() # frontier_val.json 갱신
# Phase 1..N: Evolution 루프
for iteration in range(N):
task_prompt = render_task_prompt(iteration)
# Proposer에게 새 후보 제안 요청
propose_claude(task_prompt) # → pending_eval.json + agents/<name>.py 생성
candidates = load("pending_eval.json")
valid = validate_candidates(candidates) # import 검증
# 유효한 후보만 평가
for candidate in valid:
benchmark.run(candidate.name) # 모든 데이터셋에서 val accuracy 측정
update_frontier() # frontier_val.json 갱신
update_evolution_summary() # evolution_summary.jsonl에 결과 추가
# Phase Final: Test 평가 (evolution 끝난 후 1회만)
for system in frontier_systems:
benchmark.run_test(system) # test set에서 최종 성능 측정
claude_wrapper.py (Proposer 호출 래퍼)
def run(prompt, model, allowed_tools, skills, cwd, timeout):
# 1. SKILL.md를 읽어서 system prompt에 주입
skill_text = load_skill(skills)
# 2. Claude Code CLI 명령 빌드
cmd = ["claude", "--dangerously-skip-permissions",
"-p", prompt,
"--model", "opus",
"--tools", ",".join(allowed_tools),
"--disable-slash-commands",
"--append-system-prompt", skill_text,
"--effort", "max"]
# 3. subprocess로 실행, 출력 스트리밍
proc = subprocess.Popen(cmd, cwd=cwd)
# 4. 세션 로그 저장 (claude_sessions/<timestamp>/)
save_session_logs(meta_json, response_md, tool_calls)
return SessionResult(exit_code, tokens, cost)
benchmark.py (텍스트 분류 벤치마크 실행기)
def run(memory_system_name):
for dataset in ["USPTO", "Symptom2Disease", "LawBench"]:
agent = load_agent(f"agents/{memory_system_name}.py")
# 학습 데이터로 메모리 구축
for batch in train_data:
agent.learn_from_batch(batch)
# 검증 데이터로 정확도 측정
for example in val_data:
prediction = agent.predict(example.input)
log_result(example, prediction) # log.jsonl에 기록
save("logs/{dataset}/{memory}/{model}/val.json", accuracy)
5. SKILL.md: Proposer를 조종하는 지침서
SKILL.md는 Meta-Harness에서 가장 중요한 파일이다. 논문의 Appendix D에서도 "SKILL 텍스트의 품질이 루프 동작 여부를 결정하는 가장 강력한 레버"라고 명시한다. iteration 수나 population 크기를 바꾸는 것보다 SKILL.md를 잘 쓰는 것이 효과가 더 크다. SKILL.md가 정의하는 네 가지 요소를 살펴보자.
(1) 하지 말아야 할 것
SKILL.md의 상당 부분은 proposer가 빠지기 쉬운 함정을 명시적으로 차단하는 데 할애된다. 텍스트 분류의 SKILL에서는 두 가지 주요 함정을 경고한다.
첫째, 파라미터만 바꾸는 변형 금지. 가장 흔한 실패 모드는 기존 시스템에서 숫자(검색 개수, 풀 크기, 유사도 임계값 등)만 바꾼 변형을 만드는 것이다. SKILL은 이를 명확히 금지하고, "좋은 후보는 근본적인 메커니즘을 바꿔야 한다"고 지시한다. 새로운 검색 알고리즘, 새로운 프롬프트 아키텍처, 새로운 학습 전략, 새로운 메모리 구조처럼 코드의 핵심 로직이 달라져야 한다.
둘째, 데이터셋에 치팅하는 것 금지. 데이터셋 이름을 코드에 언급하거나, 특정 데이터셋에만 도움이 되는 하드코딩을 넣는 것이 금지된다. TB2 SKILL에서도 마찬가지로, 특정 task 이름을 코드에서 참조하는 것("if task contains 'async'" 같은)을 금지한다.
(2) 만들어야 할 산출물
Proposer가 iteration을 마칠 때 반드시 생성해야 하는 파일과 그 형식을 정확히 정의한다. 텍스트 분류에서는 매 iteration마다 3개의 새 memory system을 구현해야 하고(agents/<name>.py), TB2에서는 1개의 agent variant를 구현해야 한다. 구현이 끝나면 pending_eval.json에 후보의 가설, 기반 시스템, 컴포넌트 태그 등을 기록한다.
(3) 어떤 지표를 높여야 하는가
텍스트 분류에서는 정확도(accuracy)와 컨텍스트 비용(context tokens)이라는 두 가지 목표를 동시에 고려한다. 정확도가 높으면서 컨텍스트를 적게 쓰는 것이 이상적이지만, 현실에서는 보통 트레이드오프가 존재한다. 예를 들어 예시를 많이 보여주면(높은 컨텍스트) 정확도가 올라갈 수 있지만 비용도 올라간다. Meta-Harness는 이런 트레이드오프에서 "어떤 다른 시스템에게도 모든 면에서 지지 않는 시스템들의 집합"인 Pareto frontier를 유지하면서 탐색한다. 정확도가 낮지만 비용이 매우 적은 시스템과, 정확도가 높지만 비용도 높은 시스템이 모두 frontier에 남을 수 있다.
TB2에서는 단순하게 pass rate(89개 task 중 몇 개를 풀었는가)를 높이는 것이 목표다. SKILL.md에 "Your primary goal is to improve the agent's performance (pass rate)"라고 명시되어 있다.
(4) 분석 방법은 proposer에게 맡김
흥미롭게도, SKILL.md는 "이 파일들을 읽어라"까지만 지정하고, 어떤 패턴을 찾을지, 어떤 가설을 세울지는 proposer의 판단에 맡긴다. 텍스트 분류 SKILL에서는 evolution_summary.jsonl, frontier_val.json, log.jsonl 트레이스를 읽으라고만 하고, "3개의 가설을 수립하라. 각각 검증할 수 있고 서로 다른 메커니즘을 목표로 하라"고만 지시한다.
논문의 핵심 인사이트는 이렇다. 충분한 iteration이 쌓이면, SKILL 텍스트 자체보다 축적된 실패/성공 트레이스가 proposer의 행동을 더 많이 결정한다. 초기에는 SKILL이 방향을 잡아주지만, 시간이 지나면 "지난번에 프롬프트를 바꿨더니 성능이 떨어졌다"는 경험적 데이터가 proposer의 전략을 형성한다.
6. 무엇이 기록되는가
Meta-Harness의 강점은 모든 것을 기록하고, 그 기록을 다음 iteration의 proposer가 읽을 수 있다는 점이다. 파일시스템에 저장되는 주요 파일들과 각 필드의 의미를 살펴보자.
evolution_summary.jsonl
후보 harness가 평가될 때마다 한 줄이 추가되는 append-only 로그다. 전체 진화 이력이 이 파일 하나에 누적되며, proposer는 매 iteration 시작 시 이 파일을 읽어서 "지금까지 뭘 시도했고, 뭐가 됐고, 뭐가 안 됐는지"를 파악한다.
{
"iteration": 3, // 몇 번째 iteration에서 만들어진 후보인가
"system": "contrastive_v2", // 후보 시스템 이름
"avg_val": 45.0, // 검증 데이터에서의 평균 정확도 (%)
"hypothesis": "대조 쌍이 경계 구분에 도움", // 이 후보를 만든 가설
"delta": +2.1, // 현재 최고 성능 대비 변화량 (+면 개선, -면 하락)
"outcome": "45.0% (+2.1)", // 결과 요약 문자열
"components": ["contrastive", "negative_sampling"], // 사용한 기법 태그
"timing_s": {
"propose": 450.2, // proposer가 후보를 만드는 데 걸린 시간 (초)
"bench": 1820.5, // 벤치마크 평가에 걸린 시간 (초)
"wall": 2300.8 // 전체 wall-clock 시간 (초)
}
}
TB2에서는 추가로 비용 정보(rollout_metrics)도 기록된다. 에이전트 실행은 비용이 크기 때문에 이를 추적하는 것이 중요하다.
{
"iteration": 1,
"agent": "env_bootstrap",
"avg_pass_rate": 0.465, // 89개 task 중 46.5% 통과
"hypothesis": "환경 스냅샷을 초기 프롬프트에 추가",
"delta": +0.025, // 기준선 대비 +2.5%p
"rollout_metrics": {
"n_trials": 178, // 89 task × 2 trials
"total_cost_usd": 125.43, // 총 API 비용 ($)
"mean_cost_usd": 0.705, // trial당 평균 비용
"total_input_tokens": 2105430, // 총 입력 토큰
"total_output_tokens": 890234, // 총 출력 토큰
"mean_turns": 15.3 // 평균 에이전트-LLM 대화 턴 수
}
}
frontier_val.json
현재까지 발견된 최고 성능 시스템들의 정보를 담고 있다. 데이터셋(또는 task)별 최고 시스템과, 여러 목표(정확도, 컨텍스트 비용)를 동시에 고려한 Pareto frontier를 관리한다. Proposer는 이 파일을 통해 "지금 이길 target"이 무엇인지 파악한다.
pending_eval.json
Proposer와 evaluator 사이의 통신 프로토콜 역할을 하는 파일이다. Proposer가 새 후보를 만들면 이 파일에 "이런 가설로 이런 코드를 만들었다"고 기록하고, meta_harness.py가 이 파일을 읽어서 해당 후보들을 자동으로 평가한다. 3장에서 보여준 JSON 형식이 이 파일이며, TB2에서는 약간 다른 형식을 사용한다.
{
"iteration": 1,
"candidates": [
{
"name": "tool_caching_agent",
"import_path": "agents.tool_caching_agent:AgentHarness",
"hypothesis": "반복적인 도구 호출 결과를 캐싱하면 API 호출과 컨텍스트가 줄어든다",
"changes": "_tool_cache dict 추가, _execute_commands에서 캐시 확인 후 반환",
"expected_efficiency": "API 호출 20% 감소, 출력 토큰 10% 감소 예상"
}
]
}
평가 로그 (도메인별로 다름)
위의 세 파일(evolution_summary, frontier_val, pending_eval)은 두 도메인 모두 동일한 역할로 사용되지만, 각 후보를 평가할 때 생성되는 상세 로그는 도메인별로 구조가 다르다.
텍스트 분류: logs/<dataset>/<memory>/<model>/log.jsonl
경로의 각 부분은 "어떤 데이터셋에서, 어떤 harness 후보를, 어떤 base LLM으로 평가한 결과"를 나타낸다. 예를 들어:
logs/USPTO/contrastive_retrieval/gpt-oss-120b/log.jsonl
────── ─────────────────── ─────────────
dataset memory(후보) model
이 파일에는 각 예제별로 입력 텍스트, 모델의 예측, 정답, 맞았는지 여부, 프롬프트 길이 등이 한 줄씩 기록된다. evolution_summary.jsonl이 "이 후보의 평균 정확도가 42%였다"라는 요약만 담는 반면, 이 파일은 "구체적으로 어떤 예제에서, 어떤 프롬프트로, 무엇을 예측했고, 왜 틀렸는지"를 알 수 있게 해준다.
TB2: jobs/<job-name>/<task>__<trial-N>/result.json
TB2에서는 구조가 완전히 다르다. 각 task × trial 조합마다 별도 디렉토리가 생기고, 그 안에 에이전트가 수십 턴 동안 터미널에서 작업한 전체 과정(LLM 호출, 도구 사용, 터미널 출력 등)이 기록된다. 텍스트 분류의 log.jsonl이 "입력 → 예측 → 정답"의 단순한 한 줄 기록이라면, TB2의 로그는 에이전트의 전체 행동 기록이다.
왜 이 상세 로그가 중요한가?
논문에서는 이 실행 로그 접근의 중요성을 ablation study로 검증했다. Proposer에게 점수만 보여줬을 때(scores-only)는 median 34.6%, 점수와 LLM 요약을 함께 보여줬을 때(scores+summary)는 34.9%였지만, 실행 로그 전체에 접근하게 했을 때(full Meta-Harness)는 **50.0%**로 크게 뛰었다. 요약본은 실패 원인을 진단하는 데 필요한 세부 정보를 압축 과정에서 잃어버리기 때문이다.
claude_sessions/
Proposer Claude Code 세션 자체의 전체 기록이다. meta.json에 토큰 사용량과 비용이, response.md에 proposer의 텍스트 출력이, tools/ 디렉토리에 각 도구 호출 내역이 001_Read.txt, 002_Grep.txt 같은 개별 파일로 저장된다. 논문의 Table 8에 따르면, proposer는 iteration당 중간값 82개 파일을 읽으며 소스 코드 41%, 실행 로그 40%, 점수 요약 6%, 기타 13%의 비율을 보인다.
7. Iteration 과정 상세
전체 evolution이 실행되는 과정을 처음부터 끝까지 따라가 보자.
Phase 0: Baseline 평가
Evolution 루프가 시작되기 전에, 먼저 baseline 시스템들을 평가하는 단계가 있다. 텍스트 분류에서는 no_memory(과거 예시를 전혀 사용하지 않는 직접 프롬프팅)와 fewshot_all(모든 과거 예시를 저장했다가 유사한 것을 검색해서 보여주는 few-shot 방식)을 모든 데이터셋에서 실행한다. TB2에서는 baseline_kira와 baseline_terminus2를 89개 task에서 2회 시행으로 평가한다.
이 Phase 0의 결과로 baseline의 코드, 점수, 그리고 각 예제별 실행 로그가 파일시스템에 쌓인다. Iteration 1의 proposer는 빈 상태에서 시작하는 게 아니라, 이 baseline 데이터를 읽고 "baseline이 어떤 예제에서 왜 실패했는지"를 분석해서 첫 번째 개선안을 제안한다.
Phase 1+: Evolution 루프
Phase 0이 끝나면 본격적인 evolution이 시작된다. 각 iteration은 다음 5단계를 거친다.
1단계: task prompt 생성. meta_harness.py가 proposer에게 전달할 프롬프트를 만든다. 프롬프트 자체는 매우 짧다. "iteration 3을 실행하라. 결과 파일은 이 경로들에 있다"라는 내용이 전부다. 구체적인 분석 방법이나 개선 전략은 SKILL.md에 정의되어 있고, 실제 데이터는 파일시스템에 있으므로 프롬프트에는 경로만 알려주면 된다.
2단계: proposer 호출. claude_wrapper.py가 Claude Code CLI를 subprocess로 실행한다. 이때 SKILL.md가 system prompt에 주입되고, 허용된 도구 목록이 설정되며, 작업 디렉토리가 evolution 디렉토리로 지정된다. Proposer는 최대 40분(2400초)동안 파일을 읽고, 분석하고, 코드를 작성하고, pending_eval.json을 생성한다.
3단계: 후보 검증. 제안된 후보가 실제로 실행 가능한 코드인지 확인한다. 텍스트 분류에서는 from agents.<name> import *; print('OK')를 실행해서 import가 성공하는지 확인한다. 이 단계가 없으면 문법 오류나 의존성 문제가 있는 코드도 비싼 전체 평가에 들어가게 되므로, 몇 초 만에 불량 후보를 걸러내는 중요한 안전장치다. TB2에서는 추가로 가장 간단한 task 하나(extract-elf)를 한 번 실행해보는 간단한 테스트도 수행한다. 이 간단한 테스트를 통과한 후보만 전체 89개 task 평가로 넘어간다.
4단계: 전체 평가. 검증을 통과한 후보들을 모든 데이터셋(또는 task)에서 평가한다. 텍스트 분류에서는 benchmark.py가 3개 데이터셋 × val set에서 정확도를 측정한다. TB2에서는 harbor_run()이 89개 task × 2 trials = 178번의 에이전트 실행을 수행하는데, 최대 50개를 동시에 실행해서(n_concurrent=50) 시간을 단축한다.
5단계: 결과 기록. frontier_val.json을 갱신하고, evolution_summary.jsonl에 이번 iteration의 결과를 추가한다. 새로운 최고 성능이 나왔는지 확인하고, 다음 iteration으로 넘어간다.
Phase Final: Test 평가
모든 evolution iteration이 끝나면, frontier에 있는 시스템들만 test set에서 최종 평가한다. 이 결과가 논문에 보고되는 성능 수치다. TB2에서는 5-trial로 더 정밀하게 측정한다.
8. Search Set vs Test Set
Meta-Harness에서 중요하지만 헷갈리기 쉬운 개념이 search set과 test set의 구분이다.
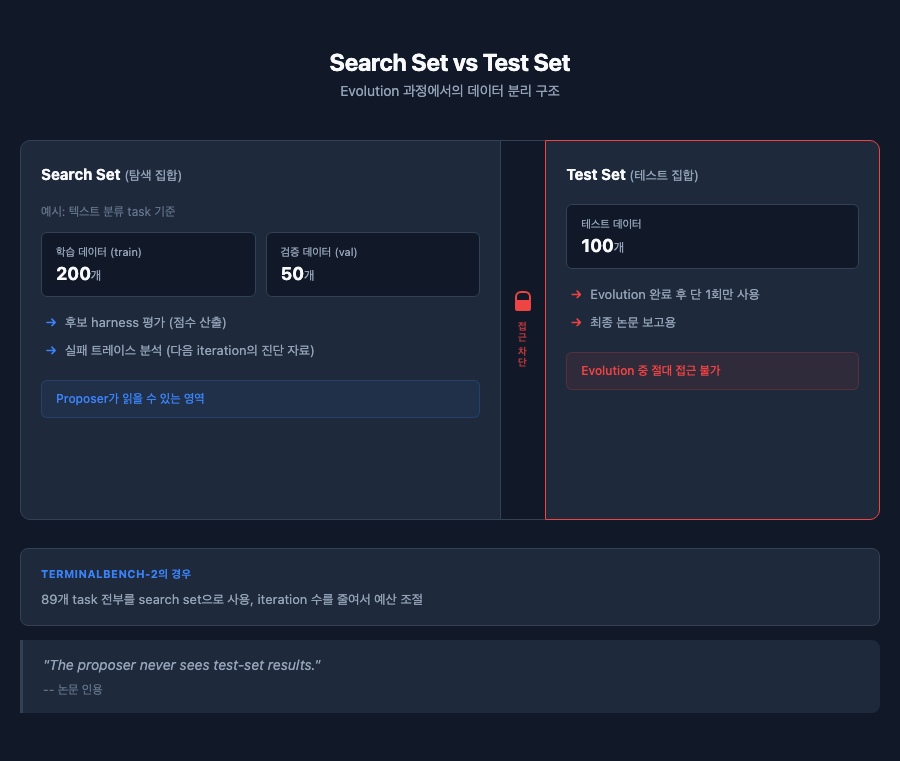
Search Set: 하나의 데이터로 두 가지 역할
Search set은 evolution 과정 전체에서 사용되는 데이터다. 텍스트 분류를 예로 들면, search set은 학습 데이터(train) 200개와 검증 데이터(val) 50개로 구성된다. 후보 harness를 평가할 때 이 데이터가 다음과 같이 사용된다.
먼저 train 200개가 순서대로 들어온다. 각 예시마다 harness가 예측을 시도한 뒤, 정답을 메모리에 저장한다. 이 과정에서 harness의 메모리에 과거 사례가 점점 쌓인다. 다음으로 val 50개가 들어오는데, 이때는 예측만 하고 메모리에 저장하지 않는다. train에서 쌓은 메모리만으로 val을 얼마나 잘 맞추는지가 해당 후보의 val accuracy가 되고, 이 점수가 evolution_summary.jsonl에 기록된다. LLM의 가중치는 전혀 바뀌지 않으며, 바뀌는 건 harness가 관리하는 예시 저장소(메모리)뿐이다.
이 과정에서 train과 val의 예제별 기록(입력, 예측, 정답, 맞았는지)이 모두 log.jsonl 하나에 쌓인다. 다음 iteration의 proposer는 이 로그를 읽고 "이 후보가 val 예시 23번에서 아스피린을 의약품이 아니라 화학물질로 예측해서 틀렸다. 프롬프트에 보여준 유사 예시 5개가 전부 화학물질이었다. 검색 로직이 잘못된 예시를 가져온 것이다" 같은 분석을 해서 다음 후보를 개선한다.
수학 검색에서는 88개 문제, TB2에서는 89개 task 전부가 search set이다. 이처럼 search set은 후보의 점수를 매기는 평가 도구이면서 동시에, 평가 과정에서 생성된 로그가 다음 iteration의 진단 자료로 쓰이는 이중 역할을 한다.
도메인별 search set 크기와 평가 비용은 다음과 같다.
| 도메인 | Search Set 크기 | 총 후보 수 | 1회 평가 비용 |
|---|---|---|---|
| 텍스트 분류 | 50-100개 예제 | ~40개 (20 iter × 2) | 저렴 (LLM 호출 몇 번) |
| 수학 검색 | 88개 문제 | ~109개 (40 iter) | 중간 |
| TerminalBench-2 | 89개 task 전부 | ~10개 (10 iter × 1) | 비쌈 (에이전트 전체 실행) |
TB2는 1회 평가 비용이 높기 때문에(에이전트가 실제로 터미널에서 과제를 수행해야 하므로), iteration 수와 후보 수를 줄여서 총 평가 예산을 조절한다. 논문의 Appendix D에서도 "search set은 실행당 대략 50회의 full evaluation이 가능할 정도로 작게 유지하라. 빠르고 판별력 있는 평가가 크고 느린 평가보다 가치 있다"고 권장한다.
Test Set: 최종 보고 전용
Test set은 evolution이 완전히 끝난 후에 단 한 번만 사용되는 데이터다. Evolution 과정 중에는 proposer도 outer loop도 test set의 결과를 절대 볼 수 없다. 논문에서도 명시적으로 "The proposer never sees test-set results; its only feedback comes from the search set"이라고 밝히고 있다.
왜 이렇게 분리하는가? 만약 test set 결과를 evolution 중에 볼 수 있다면, proposer가 test set의 특정 예제에 맞춰 하드코딩하는 오버피팅이 발생할 수 있다. Test set을 완전히 격리함으로써, 발견된 harness가 "보지 못한 데이터에서도 잘 작동하는 일반적인 전략"인지를 검증할 수 있다. 실제로 텍스트 분류에서는 탐색에 사용하지 않은 9개 새 데이터셋에서도 Meta-Harness가 73.1%로 ACE(70.2%)를 능가하여, 발견된 전략이 일반적으로 유효함을 확인했다.
코드에서도 이 분리가 명확하게 구현되어 있다. search set 결과는 logs/<dataset>/<memory>/<model>/val.json에, test set 결과는 results/<dataset>/<memory>/<model>/test.json에 별도 디렉토리로 저장되며, SKILL.md에도 test 디렉토리는 "evolution 중에 비공개"라고 명시되어 있다.
9. TB2 인과 추론: Proposer가 실패에서 배우는 과정
이 섹션은 논문에서 가장 흥미로운 부분이다(Appendix A.2). TerminalBench-2(TB2)는 LLM 에이전트가 터미널에서 복잡한 프로그래밍 과제(git 서버 설정, 데이터 파이프라인 구축, 시스템 관리 등)를 자율적으로 수행하는 89개의 어려운 task로 구성된 벤치마크다. 이 실험에서 proposer가 10번의 iteration 동안 어떻게 실패를 분석하고 전략을 바꿔나가는지를 보여준다. 단순한 무작위 시행착오가 아니라, 과학적 방법론에 가까운 추론이 일어나는 과정이다.
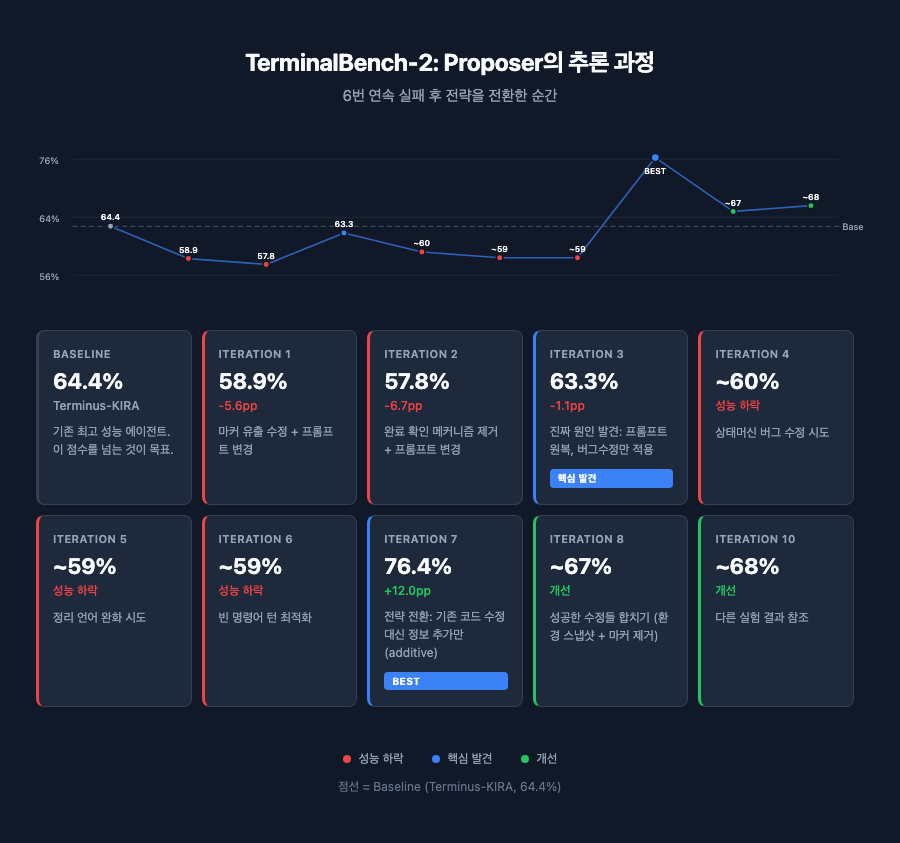
기준선은 Terminus-KIRA의 64.4% pass rate다. 이 수치가 출발점이고, 목표는 이보다 높은 pass rate을 달성하는 harness를 찾는 것이다.
Iter 1-2: 유망한 수정이 프롬프트 변경과 뒤섞임
Iter 1에서 proposer는 baseline 코드의 실행 로그를 분석하다가 버그를 발견했다. 에이전트 내부에서 LLM 호출과 터미널 출력을 구분하기 위해 사용하는 __CMDEND__ 같은 구분자 마커가 터미널 출력에 함께 섞여서 LLM에게 전달되는 문제였다. LLM이 이 의미 없는 마커를 보고 혼란에 빠져 도구를 호출하지 않는 무한 루프에 빠지는 것이었다. Proposer는 이 마커를 제거하는 수정과 무한 루프 탈출기를 추가했다. 하지만 동시에 새로운 정리(cleanup) 지향 프롬프트 템플릿과 검증 체크리스트도 도입했다. 결과는 58.9%로, 기준선 64.4%에서 5.6%p나 떨어졌다.
Iter 2에서는 에이전트가 task를 이미 풀었는데도 "정말 끝났나?" 확인을 반복하며 15~40스텝을 낭비하는 문제를 발견하고 pending-completion 메커니즘을 제거했다. 하지만 역시 마커 제거와 새 프롬프트도 함께 적용했다. 결과는 57.8%로, 6.7%p 하락. 역시 성능이 떨어졌다.
Iter 3: 진짜 원인 발견
여기서 proposer가 핵심적인 깨달음을 얻는다. evolution_summary.jsonl을 읽고 이전 두 후보의 코드와 결과를 비교한 뒤, 다음과 같이 추론한다.
"evo_marker_fix (58.9%, -5.6pp), evo_single_confirm (57.8%, -6.7pp), 둘 다 성능이 떨어졌다. 근본 원인: 프롬프트 템플릿 변경(정리 지시문)이 에이전트가 task 완료 전에 필요한 상태를 삭제하게 만들었다. 구조적 버그 수정은 유해한 프롬프트 변경과 뒤섞여 있었다."
핵심은 이것이다. Iter 1과 Iter 2는 서로 다른 버그를 고쳤는데 둘 다 성능이 떨어졌다. 그런데 두 시도의 공통점이 하나 있었다. 바로 프롬프트도 같이 바꿨다는 것이다. Proposer는 "버그 수정이 문제가 아니라 프롬프트 변경이 문제였다"고 판단하고, 프롬프트를 원래대로 되돌리고 버그 수정만 적용했다. 결과는 63.3%(-1.1pp)로, 여전히 소폭 하락이지만 이전(-5.6pp, -6.7pp)보다 훨씬 양호하여 이 판단이 맞았다는 증거가 되었다.
Iter 4-6: 기존 코드 수정 시도, 3번 연속 실패
교란 변수를 발견한 후에도 proposer는 기존 코드의 completion 로직을 직접 수정하는 시도를 계속했다. Iter 4에서는 상태 머신 버그를 수정하려 했고, Iter 5에서는 프롬프트의 정리 문구를 부드럽게 바꿔봤고, Iter 6에서는 빈 명령어 턴을 줄이는 smart-waiting을 시도했다. 세 번 모두 성능이 떨어졌다. 이 시점에서 proposer가 배운 경험적 교훈은 명확했다. 프롬프트든 완료 흐름이든, 기존 코드를 수정하면 위험하다.
Iter 7: 전략 대전환, "수정 말고 추가만!"
6번 연속 실패 후 proposer가 완전히 다른 접근법을 택한다.
"이전 6개 iteration은 모두 완료 흐름, 프롬프트 템플릿, 관측 처리를 수정해서 64.4% 기준선보다 성능이 떨어졌다.
evo_env_bootstrap은 다른 접근법, 기존 코드는 건드리지 않고 새로운 정보만 추가하는 방식을 취한다. 첫 LLM 호출 전에 단일 셸 명령어로 환경 스냅샷을 수집하여 초기 프롬프트에 덧붙인다. 다른 메서드는 변경하지 않는다."
기존 코드를 건드리지 않고, OS 정보와 설치된 패키지 목록 같은 환경 정보를 프롬프트 앞에 추가만 하는 것이다. 이미 풀리는 task에는 영향이 없고, 의존성이 복잡한 어려운 task에서만 초반 탐색 3-5턴을 절약한다. 이 후보가 최고 성능을 달성했다.
Iter 8-10: 성공한 수정들을 합치고, 다른 실험에서 배우기
Iter 8에서 proposer는 환경 스냅샷(Iter 7의 성공)과 마커 제거(Iter 3에서 검증된 수정)를 합쳤다. 두 수정은 서로 다른 문제(초반 탐색 낭비 vs 마커 유출로 인한 무한 루프)를 해결하므로, 프롬프트나 완료 흐름을 건드리지 않으면서 합치면 추가 개선이 가능하다는 판단이었다.
Iter 10에서는 더 흥미로운 일이 일어났다. Proposer가 별도의 이전 탐색 실행에서 기록된 evolution_summary.jsonl을 참조한 것이다. 그 실행에서 "'service artifact를 정리하지 마라'는 변경이 +18pp였다"는 결과가 있었고, proposer는 이 교훈을 현재 실행에 적용하려 했다. 한 번의 실험에서 배운 것을 다른 실험에서 재활용하는 것이다.
왜 이런 추론이 가능한가?
이 10번의 iteration에서 proposer가 한 일을 정리하면 이렇다. 먼저 여러 변수를 동시에 바꾼 실험의 결과를 비교해서 진짜 원인이 무엇인지 찾아냈다(Iter 3). 여러 번의 실패에서 "기존 코드를 수정하면 위험하다"는 규칙을 도출했다(Iter 4-6). 그 규칙에 따라 전략을 완전히 바꿨다(Iter 7). 과거에 성공한 수정들을 합쳤다(Iter 8). 다른 실험의 결과까지 참고했다(Iter 10).
이 모든 것은 전체 이력, 즉 모든 이전 후보의 소스 코드, 평가 점수, 실행 로그에 접근할 수 있어야만 가능하다. "점수가 58.9%였습니다"라는 한 줄 요약만으로는 왜 그 점수가 나왔는지 추론할 수 없다. Proposer는 바로 직전 시도만 보는 것이 아니라 이용 가능한 모든 이전 이력을 탐색하며, 논문의 측정에서도 이 패턴이 확인되었다.
10. 실험 결과

텍스트 분류: +7.7pp, 컨텍스트 4배 절감
비교 대상이 되는 hand-designed harness 두 가지를 먼저 설명하면, ACE(Agentic Context Engineering)는 반성적 메모리 큐레이션을 통해 시간이 지나면서 컨텍스트를 점진적으로 구축하는 시스템이고, MCE(Meta Context Engineering)는 자연어 "스킬" 라이브러리를 유지하며 진화시켜 컨텍스트를 구성하는 시스템이다. 둘 다 연구자들이 직접 설계하고 튜닝한 최신 방법이다.
Meta-Harness는 텍스트 분류에서 48.6%의 평균 정확도를 달성하여 ACE(40.9%)를 7.7pp, MCE(40.0%)를 8.6pp 앞섰다. 더 놀라운 점은 컨텍스트 사용량이다.
정확도 추가 컨텍스트 토큰
ACE 40.9% 50.8K
MCE 40.0% 28.5K
Meta-Harness 48.6% 11.4K ← 더 적은 컨텍스트로 더 높은 정확도
Meta-Harness가 ACE보다 4.5배 적은 컨텍스트를 사용하면서도 정확도는 더 높다. 많이 보여주는 게 중요한 게 아니라 뭘 보여줄지를 잘 결정하는 것이 핵심이었다는 뜻이다.
기존 텍스트 옵티마이저(OpenEvolve, TTT-Discover)와 같은 평가 예산으로 비교했을 때, Meta-Harness는 기존 방법이 40회 평가를 거쳐 도달한 최종 성능을 단 4회 평가만에 따라잡았고, 최종적으로는 10포인트 이상 앞섰다. OOD(out-of-distribution) 평가에서도, 탐색에 사용하지 않은 9개 새 데이터셋에서 Meta-Harness가 73.1%로 ACE(70.2%)를 능가하여, 발견된 전략이 특정 데이터셋에 오버피팅한 것이 아님을 확인했다.
수학 추론: +4.7pp
IMO 수준 200개 문제에서, Meta-Harness가 발견한 단일 검색 harness가 학습에 사용하지 않은 5개 모델에 걸쳐 평균 4.7pp 향상을 달성했다. 이 harness는 문제를 조합론, 기하, 정수론, 기타로 분류한 뒤 유형별로 서로 다른 BM25 검색 전략을 적용하는 4-route 라우터다. "문제 유형별로 다른 검색 전략이 필요하다"는 구조적 패턴을 사람이 설계하지 않았는데도 코드 수준에서 자동으로 발견한 것이다.
TerminalBench-2: Opus #2, Haiku #1
TB2에서 Meta-Harness는 Opus 4.6으로 76.4% pass rate를 달성하여, hand-engineered Terminus-KIRA(74.7%)를 넘어서고 모든 Opus 4.6 에이전트 중 2위를 기록했다. Haiku 4.5에서는 37.6%로 모든 Haiku 4.5 에이전트 중 1위를 차지했다. TB2는 여러 팀이 직접 최적화하는 공개 경쟁 벤치마크이므로, 자동 탐색이 이 frontier에서 의미 있는 성과를 냈다는 것 자체가 고무적이다.
11. 도메인별 SKILL 세팅이 필요하다
Meta-Harness를 새 도메인에 적용하려면 사람이 먼저 세팅해야 하는 것들이 있다. 각 도메인마다 SKILL.md, meta_harness.py, baseline harness를 별도로 작성해야 한다. 실제 코드에서도 텍스트 분류와 TB2는 완전히 다른 세팅을 사용한다.
| 구성 요소 | 텍스트 분류 | TerminalBench-2 |
|---|---|---|
| SKILL.md | MemorySystem 인터페이스 기반 | Terminus2 서브클래스 기반 |
| meta_harness.py | 데이터셋별 val accuracy 평가 | harbor로 89개 task pass rate 평가 |
| 코드 인터페이스 | predict(), learn_from_batch() | _call_llm_with_tools(), _run_agent_loop() 등 |
| baseline | no_memory, fewshot_all | Terminus-KIRA, Terminus2 |
| 후보 수/iter | 3개 | 1개 |
| 평가 비용 | 저렴 (LLM 호출 몇 번) | 비쌈 (에이전트 전체 실행) |
Meta-Harness가 자동화하는 건 "harness 코드의 탐색"이지, 이 초기 세팅 자체는 아니다. 비유하면 요리를 자동으로 개선하는 시스템이지만, "한식인지 양식인지", "재료는 뭘 쓸 수 있는지", "맛의 기준은 무엇인지"는 사람이 정해줘야 한다.
논문에서 말하는 "도메인별 하네스를 검색하며, 작업 간 리셋되는 prompt 생성, 검색, 상태 업데이트 전략"이란 이런 뜻이다. 각 task(각 문제)를 풀 때마다 harness의 내부 상태는 리셋되고, harness가 정의하는 전략(프롬프트를 어떻게 구성할지, 메모리에서 뭘 검색할지, 상태를 어떻게 업데이트할지)만 고정된다. Meta-Harness는 바로 이 전략 자체를 코드 수준에서 탐색한다.
12. 실전 팁 (Appendix D)
논문의 Appendix D는 새 도메인에 Meta-Harness를 적용할 때의 엔지니어링 교훈을 정리하고 있다.
좋은 SKILL.md를 작성하라. SKILL 텍스트의 품질이 탐색 성공 여부를 결정하는 가장 강력한 레버다. 본격적인 run 전에 3-5 iteration의 짧은 디버깅 run을 여러 번 돌려서 SKILL을 다듬는 것을 권장한다. SKILL은 산출물 형식과 금지 사항을 제약하되, 진단과 분석 방법은 proposer에게 맡겨야 한다.
Baseline이 어려워하는 Search Set을 구성하라. Baseline이 이미 잘 풀 수 있는 쉬운 문제로 search set을 구성하면 최적화할 것이 없다. Baseline이 틀리는 어려운 예제를 필터링하거나, 어려운 인스턴스의 다양한 부분집합을 선택하라. Search set은 실행당 약 50회의 full evaluation이 가능할 정도로 작게 유지하는 것이 좋다.
로그는 탐색 가능한 형식으로 저장하라. 평가 코드는 코드, 점수, 실행 로그를 JSON 같은 machine-readable 형식으로, 계층적으로 구성하여, 일관된 파일 이름으로 저장해야 한다. Proposer가 grep이나 Glob으로 원하는 정보를 빠르게 찾을 수 있도록 하는 것이 중요하다.
평가는 proposer 외부에서 자동화하라. 평가 실행은 충분히 단순하므로 proposer가 직접 할 필요가 없다. meta_harness.py가 pending_eval.json을 읽어서 자동으로 평가하고 결과를 기록하면 된다.
가벼운 검증 후 비싼 벤치마크를 실행하라. 모듈 import 테스트나 간이 실행을 통해 불량 후보를 몇 초 만에 걸러낸 뒤, 통과한 후보만 비싼 전체 평가에 넘기는 것이 비용을 크게 절약한다.
13. 마무리: 핵심 인사이트
전체 히스토리가 "왜 실패했는지" 추론을 가능하게 한다. Meta-Harness의 가장 중요한 설계 선택은 전체 이력을 파일시스템으로 노출하는 것이다. 기존 텍스트 옵티마이저가 점수 요약이나 LLM 생성 피드백만 전달하는 것과 달리, Meta-Harness는 모든 이전 후보의 소스 코드, 평가 점수, 실행 로그를 그대로 보존한다. 이것이 TB2 실험에서 본 것처럼, 여러 변수를 동시에 바꾼 실험에서 진짜 원인을 찾아내고, 반복된 실패에서 규칙을 도출하고, 과거에 성공한 수정들을 합쳐보는 추론을 가능하게 한다.
코드 공간 탐색의 힘. Meta-Harness는 프롬프트 텍스트만 바꾸는 것이 아니라 검색 알고리즘, 메모리 구조, 도구 정의, 제어 흐름 등 임의의 Python 코드를 탐색한다. 텍스트 분류에서 발견된 Draft-Verification(2단계 검증), Label-Primed Query(라벨 프라이머 + 대조 쌍), 수학의 4-route 라우터는 모두 프롬프트 수정만으로는 만들어낼 수 없는 구조적 혁신이다.
향후 연구. 현재 Meta-Harness는 base model을 고정하고 harness만 변경한다. 논문이 제시하는 자연스러운 다음 단계는 harness와 모델 가중치의 공동 진화다. 또한 현재는 Claude Code라는 특정 proposer에서만 검증되었으므로, 다른 코딩 에이전트를 proposer로 사용했을 때 효과가 어떻게 달라지는지도 열린 질문이다.
결국 이 논문이 보여주는 것은 머신러닝에서 반복되는 패턴이다. 일단 탐색 공간에 접근할 수 있게 되면, 강력한 범용 에이전트가 수작업으로 설계된 해결책을 능가할 수 있다.